
データベースとやり取りする際、毎回SQLを書いて処理するのは大変です。そこで活躍するのが ORM(Object-Relational Mapping) と JPA(Java Persistence API) です。この記事では、Spring BootにおけるSpring Data JPAの役割と、ORM・JPAの基本概念、そしてSpring BootでのJPA導入の流れをわかりやすく解説します。
📍 Spring Data JPAの位置づけ
Spring Data JPAは、Javaの標準永続化APIであるJPAをベースに、データアクセス層を簡略化するSpringの拡張機能です。Springアプリケーションでデータベース操作を行う際、従来はDAO(Data Access Object)クラスを作り、SQLやJDBCコードを直接記述する必要がありました。しかし、Spring Data JPAを使えば以下のメリットがあります。
- JPAの実装(例:Hibernate)を内部で利用:Hibernateの高度な機能を意識せず利用できる
- SQLをほぼ書かずにCRUD操作が可能:
findAll()やsave()などの共通メソッドが標準で用意される - Repositoryインターフェースを定義するだけでデータアクセス層が完成:
JpaRepositoryやCrudRepositoryを継承するだけで、即利用可能 - 命名規則ベースのクエリメソッド:メソッド名から自動的にSQLを生成(例:
findByName(String name))
これにより、データアクセスのボイラープレートコードが大幅に削減され、開発者はSQLや接続管理ではなくビジネスロジックに集中できます。さらに、JPAの抽象化によりデータベース製品を切り替える際のコード修正も最小限で済みます。
💡 補足:Hibernateとは?
HibernateはJPAの代表的な実装の1つで、Javaオブジェクトとデータベーステーブルのマッピング、SQL自動生成、キャッシュ機能などを提供する高機能なORMフレームワークです。Spring Data JPAではデフォルトでHibernateが利用されます。
💡 補足:CRUD操作とは?
CRUDは「Create(作成)」「Read(読み取り)」「Update(更新)」「Delete(削除)」の頭文字で、データベースに対する基本的な4種類の操作を指します。Spring Data JPAでは、これらの操作をsave(),findAll(),findById(),delete()などのメソッドで簡単に実装できます。
🤖 ORM(ORマッパー)の概要
ORM(Object-Relational Mapping) とは、オブジェクト指向プログラミング(Javaなど)とリレーショナルデータベース(MySQL, PostgreSQLなど)の間でデータを自動的に変換し、双方向にやり取りする仕組みです。アプリケーション側ではオブジェクトとして扱い、保存や取得の際にORMが自動でSQLに変換します。
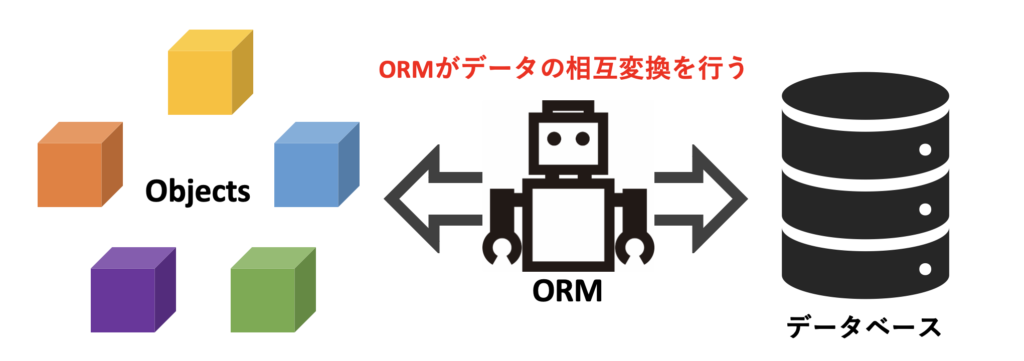
⚙️ 動作イメージ
- JavaのEntityオブジェクトにデータをセット:プログラム内で作成したエンティティインスタンス(例:
Userクラス)に、名前やメールアドレス等の実際の値を設定します。 - ORMがオブジェクトを解析してSQLを生成:設定された値を元に、該当するテーブルに対する
INSERTやUPDATE文が自動で作られます。開発者はSQL文を自分で書く必要はありません。 - データベースから取得した結果をオブジェクトに変換:
SELECT文の結果(行データ)を、ORMが対応するエンティティオブジェクト(Userなど)にマッピングし、Javaのオブジェクトとして返します。
💡 補足:Entityオブジェクトとは?
Entityは、データベースのテーブルと1対1で対応するJavaクラスのことです。フィールドはテーブルのカラムに対応し、@Entityアノテーションを付けて定義します。Spring Data JPAでは、このEntityクラスを操作することで、SQLを直接書かずにデータベースの行を作成・取得・更新・削除できます
❌ ORMを使わなかった場合 ❌
ORMを使わない場合、開発者はJDBCを直接利用して以下のような処理を行う必要があります。
String sql = "INSERT INTO users (name, email) VALUES (?, ?)";
PreparedStatement stmt = connection.prepareStatement(sql);
stmt.setString(1, user.getName());
stmt.setString(2, user.getEmail());
stmt.executeUpdate();- 全てのCRUD操作でSQL文を手動で記述する必要がある
- カラム追加・変更時はSQLやマッピング処理をすべて修正
- データ取得後のオブジェクト化も手作業で行う必要がある
このように、ORMを使わないとコード量が増え、保守性も低下します。
○ ORMを利用した場合(簡略)○
Spring Data JPAを利用すると、同じ処理は以下のように非常にシンプルに書けます。
userRepository.save(user);save()メソッドを呼ぶだけでINSERTやUPDATEが自動実行される- カラム構造の変更にも柔軟に対応可能(Entityクラスの修正のみでOK)
- データベースとのマッピングやSQL生成はすべてORMが担当
ORMのメリットデ・メリット
メリット
- SQL文の記述量を減らせる(特にCRUD処理)
- オブジェクトとテーブルの対応を自動管理
- データベース依存を減らし、異なるDB製品への移行が容易
- エンティティ設計を中心にアプリケーション開発を進められる
デメリット
- 複雑なクエリではパフォーマンスチューニングが必要
- ORMの抽象化により実行SQLが分かりにくくなる場合がある
- 設計段階でエンティティ間の関係(多対多、一対多など)を適切に定義しないと性能低下の原因になる
代表的なORMツールとして、HibernateやEclipseLinkがあります。


📕 JPAの基礎知識
JPAはJava標準の永続化APIで、データベースとのやり取りを統一的に行うためのインターフェース仕様を定めています。実装は持たず、実際の処理はHibernateやEclipseLinkなどのORMフレームワークに委ねられます。
主な要素とイメージ図
| 要素 | 説明 |
|---|---|
| Entity | テーブルと対応するJavaクラス。@Entityアノテーションでマークし、フィールドはカラムに対応。 |
| EntityManager | エンティティの保存、更新、削除、検索などを担う中心的なインターフェース。通常はEntityManagerFactoryを通して生成されます。 |
| EntityManagerFactory | EntityManagerを生成するためのファクトリクラス。データベース接続や設定情報を保持し、必要に応じてEntityManagerを提供します。 |
| 永続化コンテキスト(Persistence Context) | エンティティの状態を管理し、同一トランザクション内では同一インスタンスを保持。 |
| JPQL(Java Persistence Query Language) | SQLに似た文法でエンティティを対象に操作するクエリ言語。テーブル名ではなくエンティティ名を使用。 |
| トランザクション管理 | 一連のデータ操作を1つの処理単位として扱い、失敗時にはロールバック。 |
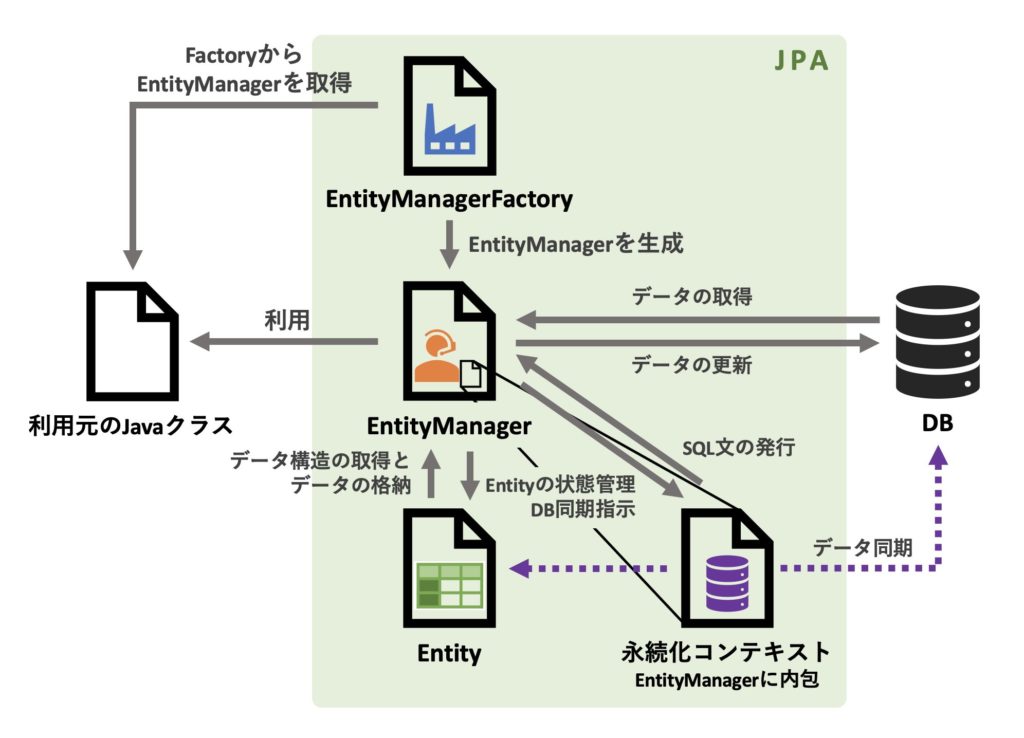
💡 補足:JPAは仕様であり、実体はない
JPAは「こういうメソッドや振る舞いを持つべき」というルールを決めただけで、動作そのものは持ちません。実際の動作はHibernateやEclipseLinkなどの実装クラスが担っています。
JPAを理解すると、ORMを使ったデータアクセスの仕組みを体系的に把握でき、Spring Data JPAを使った開発がよりスムーズになります。
🔰 Spring BootでのJPA導入の流れ
1)プロジェクト作成(Spring Initializr)
- Dependencies:Spring Web, Spring Data JPA, (開発用に)H2 Database または本番で使う MySQL/PostgreSQL Driver。
- Packaging:jar、Java 17+ を推奨。
3)依存関係(Maven/Gradle)の追加
Spring InitializrからSpring Web, Spring Data JPA, H2 Databaseを依存に追加している場合は、改めて追加する必要はありません。プロジェクトを作成すると自動的に下記の依存関係も追加されています。Spring Initializrでの追加もれや、既存のプロジェクトに導入する場合はMavenの場合pom.xml、Gradleの場合build.gradleに追加してください。
Maven
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>Gradle (Kotlin DSL)
dependencies {
implementation("org.springframework.boot:spring-boot-starter-data-jpa")
runtimeOnly("com.h2database:h2")
}💡 本番DBを使う場合:
runtimeOnly("mysql:mysql-connector-j")やruntimeOnly("org.postgresql:postgresql")に置き換えます。
3)設定(application.yml or application.properties)
spring:
datasource:
url: jdbc:h2:mem:testdb
driver-class-name: org.h2.Driver
username: sa
password:
jpa:
hibernate:
ddl-auto: update
show-sql: truespring.datasource.url=jdbc:h2:mem:testdb
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.username=sa
spring.datasource.password=
spring.jpa.hibernate.ddl-auto=update
spring.jpa.show-sql=trueMySQLの例
spring:
datasource:
url: jdbc:mysql://localhost:3306/appdb?useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Tokyo
username: app
password: secret
jpa:
hibernate:
ddl-auto: validate
properties:
hibernate.dialect: org.hibernate.dialect.MySQL8Dialect
show-sql: truespring.datasource.url=jdbc:mysql://localhost:3306/appdb?useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Tokyo
spring.datasource.username=app
spring.datasource.password=secret
spring.jpa.hibernate.ddl-auto=validate
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL8Dialect
spring.jpa.show-sql=true💡 ddl-auto の考え方:
- create:起動時にテーブルを作成(既存データは削除)
- update:差分のみ更新(既存データは保持)
- validate:スキーマの不一致を検証するだけで変更しない
- none:何もしない 学習・試作ではcreateやupdateが便利ですが、本番運用では誤ってデータや構造を変更しないようvalidateやnoneを使い、マイグレーションツールで管理するのが安全です。
4)最小のEntity / Repository(雛形)
下記のコードはSpring Data JPAの基本形です。Entityクラスはテーブル構造を表し、RepositoryインターフェースはCRUD操作を自動で提供します。初心者はまずこの形を覚えておけば、シンプルなデータ操作が可能になります。
@Entity
public class User {
@Id @GeneratedValue
private Long id;
private String name;
protected User() {} // JPA仕様上、デフォルトコンストラクタが必要
public User(String name) { this.name = name; }
public Long getId() { return id; }
public String getName() { return name; }
}
public interface UserRepository extends JpaRepository<User, Long> {}💡
JpaRepositoryを継承するだけで、saveやfindAllなどのメソッドが自動で利用可能になります。saveはエンティティの新規登録・更新を行い、findAllは全件取得を行います。
4) 動作確認(スモークテスト)
最後にSpring Bootアプリケーションが正しくデータベースにアクセスできるかを簡易的に確認します。CommandLineRunnerを使い、アプリ起動時にUserRepository経由でデータ登録と件数取得を行い、コンソールに出力します。これにより、JPA設定やDB接続が正しく機能しているかを素早く検証できます。
@SpringBootApplication
public class App {
public static void main(String[] args) { SpringApplication.run(App.class, args); }
@Bean CommandLineRunner init(UserRepository repo) {
return args -> {
repo.save(new User("Taro"));
System.out.println("users=" + repo.count());
};
}
}つまづきポイント‼️
| エラー内容 | 原因 | 修正方法 |
|---|---|---|
| Failed to configure a DataSource | 接続情報の未設定 | spring.datasource.url など必要な設定を追加 |
| Dialect not set | hibernate.dialect の未指定 | DBに合ったDialectを設定 (MySQL8Dialect など) |
| Table not found | ddl-auto=noneやvalidateでテーブル未作成 | 開発時はcreateやupdateに変更、または手動でテーブル作成 |
まとめ
本節では、Spring Data JPA を理解するための土台として、ORM の仕組みと JPA の役割を紹介しました。ORM を活用することで、SQL に依存した実装から解放され、ドメインモデルと一貫性のある形でデータベースアクセスを実現できます。
次回の記事では、最小構成で作成したEntityとRepositoryを発展させながらSpring Data JPA の活用方法を詳しく見ていきます。






