
Node.jsはシングルプロセスがシングルスレッドで実行されます.基本的にスレッドは一つのCPUで動作します.もしサーバーに4コアCPUが備わっている場合,シングルスレッドでは3つのCPUコアが使われないことになってしまいます.これはCPUを有効活用できていなく,多数のリクエストが来た場合でもCPUをフル活用できません.本記事はNode.jsでマルチプロセス化する方法を解説していきます.
クラスタリングによるマルチプロセス化
CPUを有効活用するためにNode.jsでは,クラスタリングと呼ばれる方法でCPUコアを無駄なく活用することができます.こちらのコードを見て下さい.
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
// Fork workers.
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`);
});
} else {
// Workers can share any TCP connection
// In this case it is an HTTP server
http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world\n');
}).listen(8000);
console.log(`Worker ${process.pid} started`);
}
$ node server.js
Master 3596 is running
Worker 4324 started
Worker 4520 started
Worker 6056 started
Worker 5644 startedこのコードはプロセスのIDをターミナルに出力します.まずはマスタープロセスがfor文でCPUの数だけ子プロセスを生成しています.ここで生成した子プロセスのことをworkerと呼びます.
cluster.fork();ここの行が実際にworkerを生成している部分になります.またclusterにexitイベントを設定して,workerが消去された時,ターミナルにworkerIDと消去したメッセージを出力するようにしています.
ここで注目して欲しいのが,マスタープロセスはworkerを生成しているだけで,実際にサーバーを生成しているのは各々のworkerになっています.
最後,生成したworkerのサーバーをスタートさせたことをworkerIDと一緒に出力しています.
この方法を使えばマルチプロセス化でき,CPUコアの数だけworkerを生成することで,CPUコアを有効活用することができます.
workerの「schedulingPolicy」による負荷分散
cluster.fork()を使えば簡単にworkerが生成できることがわかりましたが,そのworkerにはどのようにアクセスが振り分けられるのでしょうか.それは「cluster.schedulingPolicy」で設定することができます.以下のコードを見てください.
const cluster=require('cluster');
cluster.schedulingPolicy = cluster.SCHED_RR;「cluster.schedulingPolicy」の設定はグローバル設定です.設定できる値は2つあります.
- cluster.SCHED_RR
- cluster.SCHED_NONE
「cluster.SCHED_RR」はラウンドロビンです.ラウンドロビンとはアクセスを各workerに均等に振り分けることです.「cluster.SCHED_NONE」はOSに任せる設定となります.デフォルトでは「cluster.SCHED_RR」が設定されています.
workerの消滅に伴う自動再起動
workerをCPUコアの数だけ生成し,負荷分散もできるようになりました.しかし,あるworkerが異常終了(killと呼ぶ)した場合,代わりとなるworkerが生成されません.そうなるとCPUコアを有効活用できずに処理が進んでしまいます.これを防ぐために,workerに終了イベントを設定し,workerが異常終了した場合に「cluster.fork()」でworkerを補填します.
以下のコードを見てください.先程のクラスタリングのコードに負荷分散と自動再起動を組み込んだコードになります.
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
cluster.schedulingPolicy = cluster.SCHED_RR;
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
// Fork workers.
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log('worker %d died (%s). restarting...',
worker.process.pid, signal || code);
//workerが異常終了した場合にworkerを補填する
if ( code !== 0 && !worker.exitedAfterDisconnect){
cluster.fork();
}
});
} else {
http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world\n');
}).listen(8000);
console.log(`Worker ${process.pid} started`);
}
clusterの終了イベントのコールバック関数のcodeには異常終了した場合,0以外の数字が入ります.「worker.exitedAfterDisconnect」は異常終了(.kill() またはdisconnect())した場合,trueを返します.このプロパティで自発的終了か偶発的終了かを判断します.偶発的終了と判断した場合のみ,workerを再生成します.
実際にコードを実行し,別のターミナルで以下のコマンドを実行してworkerをkillしてみましょう.
kill 任意のworkerID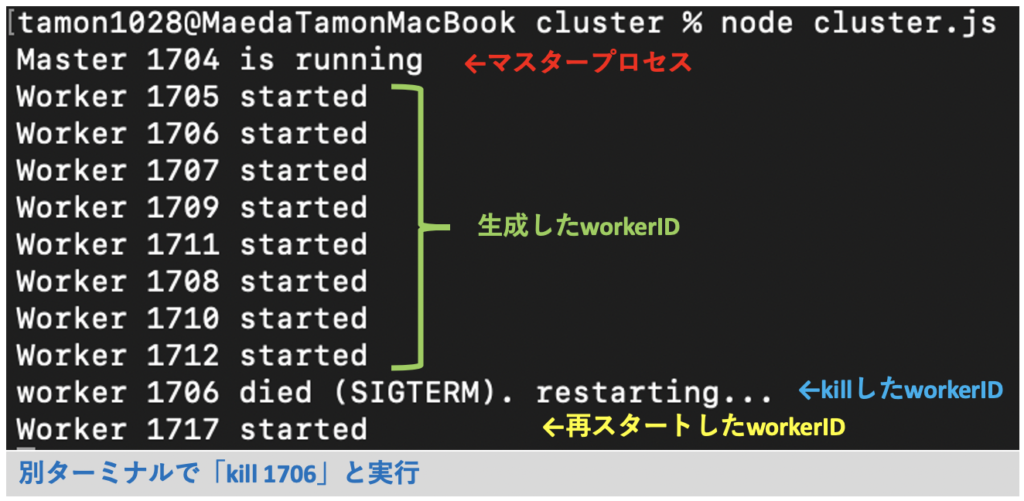
workerが異常終了した場合しっかりと新しいworkerが生成されています.これでNode.jsにおけるCPUを有効活用するクラスタリングの解説は終了です.
この記事は以下のサイトを参考にしています.
Node.js v14.5.0 Documentation Cluster
https://nodejs.org/api/cluster.html#cluster_event_exit_1







コメント